RAG是什麼?他是如何帶領LLM走向下一階段的
- 2025年5月5日
- 讀畢需時 7 分鐘
已更新:2025年7月21日

在生成式 AI 熱潮中,RAG( Retrieval-Augmented Generation ) 已成為企業、開發者與資料科學團隊爭相採用的技術架構。這篇文章將詳細介紹 RAG的定義、RAG的運作原理、現在有哪些RAG類型、現在面臨的挑戰有哪些。
文章導覽:
一、RAG 是什麼 ?
(一)RAG 背景調查
RAG 全名為“Retrieval-Augmented Generation” ,中文叫做 “檢索增強生成” 。它是一種結合外部知識庫的生成式 AI 架構。其目的是減少大語言模型(LLM)在回答時可能出現的幻覺 & 知識不足的問題。
簡單來說,RAG 可以視為一種工作流程或行為模式。當用戶向 LLM 提出一個查詢(Query)時,模型會先到外部知識庫中檢索相關資料,然後將這些檢索結果與 LLM 本身內建的知識結合,作為回覆用戶的依據,使答案更完整、精確且有根據。
< 延伸學習 > LLM 是什麼?從基礎到實戰,帶你全面了解什麼是大語言模型
(二)企業為什麼會需要RAG ?
傳統大語言模型( LLM ) 知識來源是來自其建立時所訓練的資訊,但這就會產生一些問題:資料過時、AI 亂猜等問題。為解決這些缺點,RAG 就此誕生。他的幾項特色將有效降低 LLM 原有的問題:
能解決資料過時問題
只要定期更新知識庫內的內容將能一直提供 LLM 最新知識,不再有知識時效性。這將大大降低重訓成本。
能降低 AI 幻覺
RAG 利用檢索到的真實資料輔助回答,能降低模型「捏造答案」的機率,然而,其實還是有機會產生 AI幻覺。
涵蓋長尾知識,處理冷門問題
可針對冷門、專業的主題放入知識庫中,能大幅提升 AI 在罕見問題或小眾領域的解答能力,解決 LLM 單靠訓練語料時難以覆蓋的盲點。
具資料追朔性
RAG 的回答來自明確的來源,可以附上引用連結或資料出處,讓用戶能自行驗證,提升信任感。
可內部私有化
RAG 可導入公司內部 FAQ、產品文件、政策手冊等進入私有的向量數據庫中,讓模型回答與公司實務有關的專屬問題,更貼近實際商業需求。
二、RAG 的運作原理
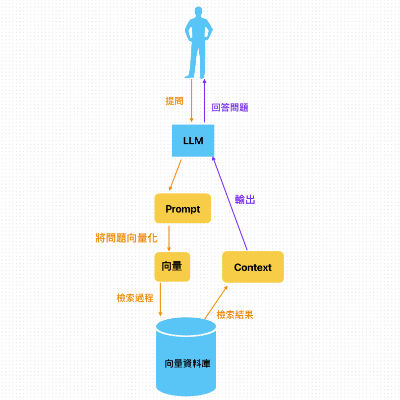
RAG 運作流程主要分為兩部分進行:1. 知識儲存環節 2.用戶提問環節。透過兩者相互結合,共同構成完整的RAG 架構。
(一)知識儲存環節
RAG 為了實現語意相似檢索,因此他的作法為建立向量知識庫。透過此讓模型快速找到最相關的外部資料。那要如何建立向量知識庫呢 ?
先將所需資料文本進行分段,得出若干個段落,這也就是chunks
將若干個chunks 進行向量化 (Embedding),此舉是為了把文字或其他非結構化資料(如圖片、聲音)轉換成機器能理解的「數學向量」形式,以便進行比對、分析與運算
當進行向量化後可得到一堆向量,最後就可以將其放入向量資料庫中以供查詢
💡 此環節具備 RAG 哪些特性?
能解決資料過時問題
能降低 AI 幻覺
涵蓋長尾知識,處理冷門問題
可內部私有化

(二)用戶提問環節
當用戶對 LLM 進行提問後,RAG會先將問題向量化成向量
將向量化的問題對向量資料庫進行檢索,查詢相似度最高的向量答案
將向量答案輸出成Context
將Context 與 問題轉化成 Prompt 給 LLM 進行答案生成
💡 此環節具備 RAG 哪些特性?
具資料追朔性
三、2025 年,哪些資料可以放入向量知識庫中 ?
過去的向量知識庫因受限於技術,最初只能將結構性資料放入此中,像是:
技術文件、FAQ、白皮書、使用手冊
部落格文章、新聞報導
產品描述、客服記錄
隨著技術的進步,RAG 的應用也逐漸擴展,不再侷限於文字資料,而是演化出各種新型態的 RAG 架構,能處理更多元的資料來源與應用情境。
(一)可以將哪些資料放入向量知識庫中
隨著多模態技術的成熟,目前 RAG 已經可以處理:
純文字資料:文件、FAQ、筆記、聊天記錄等
圖片與圖表:經由 CLIP、BLIP 等模型向量化的圖像
音訊與影片:音訊轉文字後檢索,或影片截圖轉向量
程式碼與結構化資料:API 文件、JSON、表格描述
< 延伸學習 > 2025 向量資料庫推薦:建立RAG 的核心技術
(二)2025年目前 RAG 的發展方向有哪些?
隨著生成式 AI 與向量資料庫技術的成熟,RAG(Retrieval-Augmented Generation)架構正快速演進,衍生出多種強化版本,以因應不同產業場景與複雜知識需求。以下為目前主流的進階 RAG 類型介紹:
🔹 多模態 RAG(Multi-modal RAG)
多模態 RAG 結合圖像、文字、音訊、影片等不同形式資料的檢索與生成能力。它能將圖片或影片的特徵向量與文字資料一同儲存在向量資料庫中,實現跨模態檢索與回答。例如,使用者可用文字描述查找相關圖片,或用圖片檢索對應的說明文件。
🔹 GraphRAG
GraphRAG 將檢索結果結合知識圖譜(Knowledge Graph)結構,強化資料間的關聯推理與路徑導引。這類架構除了基於語意相似度檢索,還能根據知識圖的節點、邊關係進行多跳查詢與推論,使答案具備更高的邏輯一致性與可解釋性。
🔹 Agentic RAG
Agentic RAG 結合了 Agentic AI 的理念,讓 RAG 系統具備類智能體(Agent)的自我導引與規劃能力。它不僅檢索與生成,更能根據目標動態決定檢索策略、調用多輪查詢、彙整多模態資料來源,甚至自訂中間推理步驟,以達到更精準、靈活的應用效果。
< 延伸學習>
四、RAG 技術發展的挑戰與待解決問題
(一)RAG 技術發展的挑戰
雖然Retrieval-Augmented Generation(RAG)技術已成為企業智慧應用的重要基礎,但在實際應用與大規模部署時,仍有多方面挑戰需要克服,以下為幾項主要挑戰:
1️⃣ 多模態與混合檢索的分數融合挑戰
在 Multi-modal RAG 或 Hybrid RAG 架構中,如何合理融合不同模態(圖、文、音)或不同檢索策略(向量相似度、關鍵字布林查詢)的分數,是一大挑戰。分數融合不當可能導致「好資料沒被選中」,或「無關資料被過度強化」,影響最終生成的精確度。
2️⃣ 動態知識更新與版本控管
RAG 的優勢之一是可以接入最新資料,但這也帶來資料更新頻率、版本控管的挑戰。例如,知識庫更新後,如何快速重新向量化並保證新舊資料一致性?如何避免因舊版本向量殘留導致回答過時或矛盾
3️⃣ 計算資源與延遲問題
在實務應用中,多模態向量檢索、雙階段 re-rank、動態 tool-calling 等操作可能造成響應延遲、資源消耗過大,特別是在大規模用戶並發或邊緣部署環境中。如何在準確性與效能間取得平衡,是落地部署時的重要挑戰。
(二)未來解決方向
為解決上述挑戰,業界正在持續探索的方向包括:
更高品質的嵌入模型與資料前處理流程
動態向量更新與版本化向量庫
多模態與混合檢索的分數學習融合(Learning to Rank)
生成引用強化與追溯可視化(如 source-grounded answer highlighting)
計算優化與邊緣友好型架構
更細緻的存取控管與資料隱私強化機制
五、 RAG & Fine-tuning
(一)何謂 Fine-tuning
Fine-tuning 是指在已訓練好的LLM 上,透過使用特定領域的資料進行重新訓練模型參數,以便讓模型能更精確地理解並生成該領域的內容。
(二)RAG & Fine-tuning 的差異
| RAG | Fine-tuning |
基本概念 | 查資料 + 生成回應 | 重新訓練模型參數 |
運作方式 | 模型從外部知識庫檢索內容,再融合回答 | 使用特定資料對模型重新訓練 |
資料依賴 | 依賴知識庫品質與檢索效果 | 依賴訓練資料品質與標註準確性 |
彈性 | 知識更新簡單,只要改知識庫即可 | 更新需重新訓練模型 |
由此可知,RAG 適合需要快速更新、強調資料溯源的應用場景;Fine-tuning 則適合針對特定任務或風格長期調整模型表現。
< 延伸學習>
六、總結:RAG 是 AI 知識應用的關鍵解法
RAG 不只是大型語言模型的輔助工具,更是讓 AI 理解、更新與引用企業資料的關鍵架構。隨著技術演進,它已從文字走向多模態,並逐步具備圖譜推理、工具操作等能力,成為企業打造智慧助理與知識工作流的核心基礎。未來,想讓 AI 真正理解你的業務,RAG 將是不可或缺的第一步。
💡 Q&A:
為什麼以前chatgpt資料查不到最新的,但現在可以?
因為 OpenAI 新增了「Browser Tool」功能,讓 ChatGPT 能連上網路進行即時查詢。這項功能類似 RAG 的概念:在使用者提問時,ChatGPT 會即時搜尋網站、新聞與文件內容,並融合搜尋結果生成回應,達成與最新資訊同步的效果。
傳統資料庫&向量資料庫差別差在哪啊 ?
傳統資料庫:傳統資料庫中,文字雖然也是以數字編碼的方式儲存,但這種編碼只是為了「識別」,而非「理解」。
向量資料庫:向量資料庫的核心在於,將文字、圖片、語音等非結構化資料透過模型轉為「向量」,這些向量能保留語意資訊,讓系統具備「模糊比對」與「語意搜尋」的能力。
為什麼需要向量數據庫呢?
因為當你想讓 AI「看得懂」資料、並根據語意找出相關資訊時,傳統資料庫根本做不到這件事。向量資料庫是 AI 理解世界的基礎結構,尤其是像 RAG(檢索增強生成)這種需要語意檢索的流程中,少了向量資料庫,就無法進行有效的資料匹配與生成輔助。
🌟 參考資料:
IBM ( YouTube ) :


留言